
Project Overview
In this project I trained several models to detect fraud transactions. I have started 5 baseline models. Those are, LogisticRegression, KNeighborsClassifier, RandomForestClassifier, XGBClassifier, SupportVectorMachine Classifier. I continued to optimize top two models based on their train and test accuracy result. XGBoost and RandomForest Models. I have done five iterations including grid search on hyperparameters, balancing the labels by SMOTE and subsampling from the original dataset. Both RandomForest and XGBoost model had over 99% accuracy on the data that includes all frauds and some random safe data. The data was still imbalanced so I did SMOTE over this dataset as well. At the end of those iterations, XGBoost model had 99% accuracy on both train and test sets.
Project Steps
- 1.Loading Data and EDA
- 2.Feature Engineering
- 3.Machine Learning
- 3.1. Baseline Models
- 3.2. Grid Search for Best Hyper-parameter
- 3.3. Dealing with Unbalanced Data
- 3.3.1. Balancing Data via Resambling with SMOTE
- 3.3.2. Subsampling Data from the Original Dataset
- 3.3.3 Performing SMOTE on the New Data
- 4.Machine Learning Pipeline
- 5.Feature Importance
- 6.Conclusion
Data
I used Kaggle’s Paysim dataset. It simulates mobile money transactions based on a sample of real transactions extracted from one month of financial logs from a mobile money service implemented in an African country. The original logs were provided by a multinational company, who is the provider of the mobile financial service which is currently running in more than 14 countries all around the world.
https://www.kaggle.com/ntnu-testimon/paysim1
Dataset has fillowing columns:
step - maps a unit of time in the real world. In this case 1 step is 1 hour of time. Total steps 744 (30 days simulation).
type - CASH-IN, CASH-OUT, DEBIT, PAYMENT and TRANSFER.
amount - amount of the transaction in local currency.
nameOrig - customer who started the transaction
oldbalanceOrg - initial balance before the transaction
newbalanceOrig - new balance after the transaction
nameDest - customer who is the recipient of the transaction
oldbalanceDest - initial balance recipient before the transaction. Note that there is not information for customers that start with M (Merchants).
newbalanceDest - new balance recipient after the transaction. Note that there is not information for customers that start with M (Merchants).
isFraud - This is the transactions made by the fraudulent agents inside the simulation. In this specific dataset the fraudulent behavior of the agents aims to profit by taking control or customers accounts and try to empty the funds by transferring to another account and then cashing out of the system.
isFlaggedFraud - The business model aims to control massive transfers from one account to another and flags illegal attempts. An illegal attempt in this dataset is an attempt to transfer more than 200.000 in a single transaction.
1.Loading Data and EDA
import os
import math
from numpy import *
import numpy as np
import pandas as pd
import random
import seaborn as sns #for visualization
import matplotlib.pyplot as plt #for visualization
#Load data
data=pd.read_csv('paysim.csv')
#Check if there is anu null values
data.isna().sum().sum()
0
#check for duplicate values
data.duplicated(keep='first').any()
False
There are no duplicate rows, so we do not need to worry about duplicated data.
Examine the data by the labels
I will filter the data by the labels and examine two groups compairing each other.
# Filter data by the labels. Safe and Fraud transaction
safe = data[data['isFraud']==0]
fraud = data[data['isFraud']==1]
See the frequency of the transactions for each class on the same plot.
plt.figure(figsize=(10, 3))
sns.distplot(safe.step, label="Safe Transaction")
sns.distplot(fraud.step, label='Fraud Transaction')
plt.xlabel('Hour')
plt.ylabel('Number of Transactions')
plt.title('Distribution of Transactions over the Time')
plt.legend()
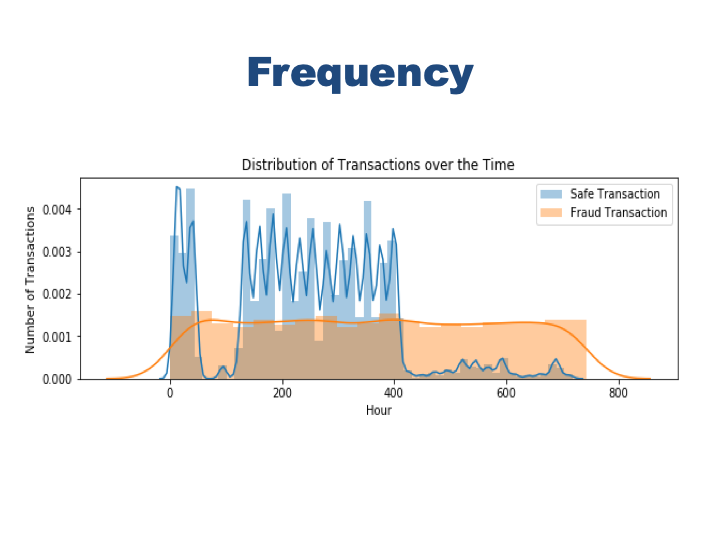
Eventhough safe transactions slows down in 3rd and 4th day and after 16th day of the month, fraud transactions happens at a steady pace. Especially in the second half of the month there are much less safe transactions but number of fraud transactions does not decrease at all.
Hourly Transaction Amounts
#just use small portion of data to scatterplot the transaction happens every hour and their amount.
smalldata=data.sample(n=100000, random_state=1)
smalldata=smalldata.sort_index()
smalldata=smalldata.reset_index(drop=True)
#plot the small data
plt.figure(figsize=(18,6))
plt.ylim(0, 10000000)
plt.title('Hourly Transaction Amounts')
ax = sns.scatterplot(x="step", y="amount", hue="isFraud",
data=smalldata)
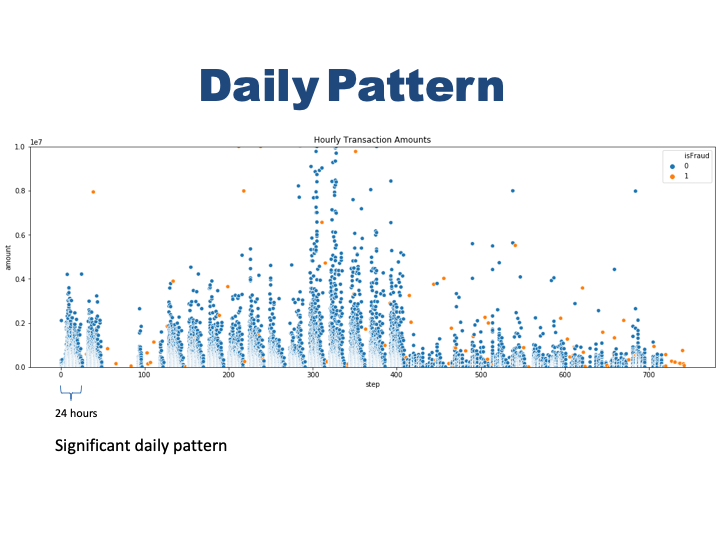
The plot clearly shows that there is some sort of seasonality in the number of transaction during the day. We observe a pattern every 24 hours. we do not know what time of the day ‘0’ represent here but we observe highest transactions clusters around the middle of 24 hour period. It mught be noon or mid day. Lets see if fraud transactions has that kind of pattern.
#The hourly amount of al fraud transactions
plt.figure(figsize=(18,6))
plt.ylim(0, 10000000)
plt.title('Hourly Fraud Transaction Amounts')
ax = sns.scatterplot(x="step", y="amount", color='orange',
data=fraud)
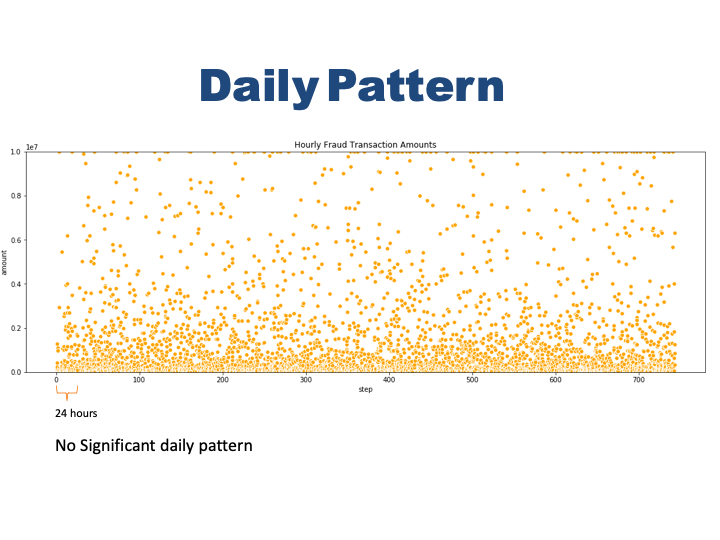 

Fraud transactions does not show that significant pattern like safe ones in terms of number of accurance. They happen every hour almast in the same frequency. There are more fraud transactions in low amounts and less in high amount. But the pattern does not change time to time.
Transaction Amount Distributions
There is an interesting peak on 1M$. Lets see how many fraud transactions happens at 1M$. Safe transactions also more often in the low amounts . There is a peek in 1M dolar but above that the frequency decreases.
# fraud transactions amount value counts
fraud.amount.value_counts()
10000000.00 287
0.00 16
429257.45 4
1165187.89 4
76646.05 2
...
3576297.10 1
23292.30 1
1078013.76 1
112486.46 1
4892193.09 1
Name: amount, Length: 3977, dtype: int64
There are fraud transactions in $1M amount for 287 times. And this is the max amount of fraud transactions. Most of the frauds happens below $400000 so lets check the average amount for those transactions.

Fraud transaction happens in a large range such as $119 to 10M. The Frequency distribution of Amount of money involved in Fraud transactions is Positively Skewed. Most of the fraud transactions are of Lesser amount. Majority of fraud transactions are lower than 1M. But in 1M there is an interesting increase similar to safe transactions. And that is also max amount in all fraud incidents. There are also some fraud labeled transaction that have 0 amount. This is strange. I want to see those instances, there are 16 of them.
They are definetely not correct data. But it might have some sort of value such as creating some noise in the transaction traffic to make the real fraud not to be noticed. For that reason I will keep this data.
Type of Transactions
#checking type of fraud transactions
fraud.type.value_counts()
Out[28]:
CASH_OUT 4116
TRANSFER 4097
Name: type, dtype: int64
Fraud activities only happens with transfer and cash_out transactions. Debit usage is very safe. It will be better to use only Transfer and Cash_out transaction data for our model since the other types has no fraud.
Rate of Fraud Transactions
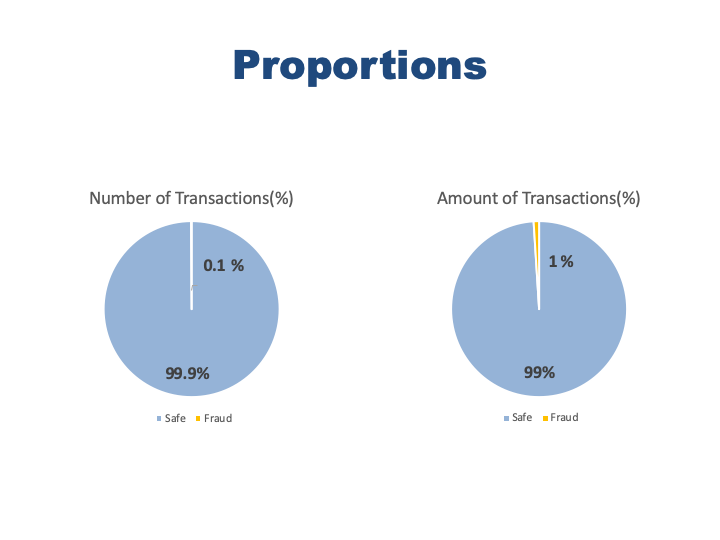
#proportion of number of frauds
data.isFraud.value_counts()[1]/(data.isFraud.value_counts()[0]+data.isFraud.value_counts()[1])
0.001290820448180152
Fraud transactions are only 0.01% of the safe transactions. Target class is pretty skewed. It might be problem in the model but we will see.
#proportion of fraud amount
fraud.amount.sum()/(safe.amount.sum()+fraud.amount.sum())
0.010535206008606473
Total money was stolen is 0.1% of safe transaction amount.
2. Feature Engineering
First only get Transfer and Cash_out transaction data¶ Since fraud transactions happens only in these type of transactions, I will use only that data.
#filtering only transfer and cash_out data
data_by_type=data[data['type'].isin(['TRANSFER','CASH_OUT'])]
This data is too big to work with a machine learning algorithm. I will get random subsample from this dataframe just big enough to built a machine learning model. For such project 100000 instance would be good.
#subsample data , get 100000 instances to train model
df=data_by_type.sample(n=100000, random_state=1)
df=df.sort_index()
df=df.reset_index(drop=True)
Dealing with name columns
nameOrig and nameDest columns are supposed to be the names of the peeople. At this moment, they can not be used in machine learning model. But if there is any repeting transaction between two people that might me useful information for classifier.I can create a new column with numeric value with repeat info. Let me check.
#checking if there is any repetes transaction in between two parties.
list1=np.array(df.nameOrig)
list2=np.array(df.nameDest)
list3=list1+list2
repeat=pd.DataFrame(list3, columns=['comb'])
comb_cnt=repeat.comb.value_counts()
comb_cnt.value_counts()
1 100000
Name: comb, dtype: int64
Well, there is no repeated transaction between 2 parties, each of them are unique. So, we can just drop these string columns.
#drop the name columns
df=df.drop(['nameOrig', 'nameDest'], axis=1)
#Binary-encoding of labelled data in 'type'
df.loc[df.type == 'CASH_OUT', 'type'] = 1
df.loc[df.type == 'TRANSFER', 'type'] = 0
There is something wrong with the balance information. Eventhough a transaction going on both old and new balance looks ‘0’. But I will ignore it for now.
3. Machine Learning
from sklearn.model_selection import train_test_split # import train_test_split function
from sklearn.linear_model import LogisticRegression # import LogisticRegression
from sklearn.metrics import classification_report, accuracy_score, roc_auc_score # import accuracy metrics
from sklearn.ensemble import RandomForestClassifier #import RandomForestClassifier
from sklearn import svm #import support vector machine classifier
import xgboost as xgb
from xgboost import XGBClassifier #import xgboost classifier
from sklearn.neighbors import KNeighborsClassifier #import KNeighborsClassifier
from sklearn.model_selection import GridSearchCV # import GridSearchCV
# suppress all warnings
import warnings
warnings.filterwarnings("ignore")
#Slice the target and features from the dataset
features=df.drop('isFraud', axis=1)
target =df.isFraud
# split the data into train and test
X_train, X_test, y_train, y_test = train_test_split(features, target, test_size=0.2)
3.1. Baseline Models
First, I will run five classification madel with their default parameter to see how each one perform. I put all the classifers into a list and train them in a loop. ml_func function handles all train, evaluation and storing the performence metrics. Also, the data is highly unbalanced, the positive class (frauds) account for 0.01% of all transactions. So I will be measuring the accuracy using the Area Under the Precision-Recall Curve (AUPRC). Confusion matrix accuracy is not meaningful for unbalanced classification.
# General function to run classifier with default parameters to get baseline model
def ml_func (algoritm):
#train and fit regression model
model=algoritm()
model.fit(X_train, y_train)
# predict
train_preds = model.predict(X_train)
test_preds = model.predict(X_test)
# evaluate
train_accuracy = roc_auc_score(y_train, train_preds)
test_accuracy = roc_auc_score(y_test, test_preds)
#report = classification_report(y_test, test_preds)
print(str(algoritm))
print("------------------------")
print(f"Training Accuracy: {(train_accuracy * 100):.4}%")
print(f"Test Accuracy: {(test_accuracy * 100):.4}%")
# store accuracy in a new dataframe
score_logreg = [algoritm, train_accuracy, test_accuracy]
models = pd.DataFrame([score_logreg])
#list of all classifiers that I will run for base models
algoritms=[LogisticRegression,KNeighborsClassifier,RandomForestClassifier,XGBClassifier,svm.SVC]
#running each model and print accuracy scores
for algoritm in algoritms:
ml_func (algoritm)
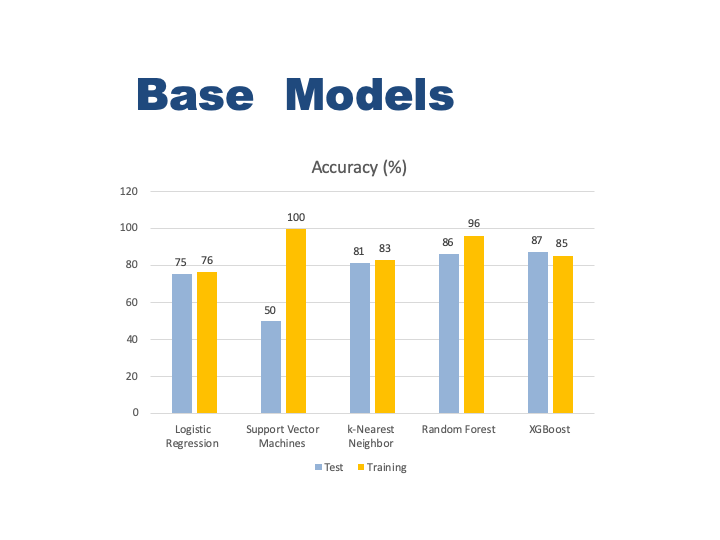
3.2. Grid Search for Best Hyper-Parameter
In the above report we see the best training accuracy is from Random Forest Classifier. On the other hand the best test accuracy is from XGBoost Classifier. I would like to optimize these two model with grid search of multiple parameter values. Grid earch will help me to figure our best parameters to pass to the model to get the most accurate result. I will create a function for grid search named best_param. It will take parameter values and the classifer and print our the best parameter combinations. I will only run Random Forest and XGBoost models for the rest of the project since they are the best two.
#A general function for grdi search
def grid_src(classifier, param_grid):
param_grid=param_grid
# instantiate the tuned random forest
grid_search = GridSearchCV(classifier, param_grid, cv=3, n_jobs=-1)
# train the tuned random forest
grid_search.fit(X_train, y_train)
# print best estimator parameters found during the grid search
print((str(classifier) + 'Best Parameters'))
print("------------------------")
print(grid_search.best_params_)
return grid_search.best_params_
#Grid Search for best parameters of RandomForestClassifier
param_grid_rf = {'n_estimators': [10, 80, 100],
'criterion': ['gini', 'entropy'],
'max_depth': [10],
'min_samples_split': [2, 3, 4]
}
rf_params=grid_src(RandomForestClassifier(),param_grid_rf)
RandomForestClassifier(bootstrap=True, class_weight=None, criterion='gini',
max_depth=None, max_features='auto', max_leaf_nodes=None,
min_impurity_decrease=0.0, min_impurity_split=None,
min_samples_leaf=1, min_samples_split=2,
min_weight_fraction_leaf=0.0, n_estimators='warn',
n_jobs=None, oob_score=False, random_state=None,
verbose=0, warm_start=False)Best Parameters
------------------------
{'criterion': 'entropy', 'max_depth': 10, 'min_samples_split': 4, 'n_estimators': 10}
#Grid Search for best parameters of XGBClassifier
param_grid_xg = {'n_estimators': [100],
'learning_rate': [0.05, 0.1],
'max_depth': [3, 5, 10],
'colsample_bytree': [0.7, 1],
'gamma': [0.0, 0.1, 0.2]
}
grid_src(XGBClassifier(), param_grid_xg)
XGBClassifier(base_score=0.5, booster='gbtree', colsample_bylevel=1,
colsample_bynode=1, colsample_bytree=1, gamma=0,
learning_rate=0.1, max_delta_step=0, max_depth=3,
min_child_weight=1, missing=None, n_estimators=100, n_jobs=1,
nthread=None, objective='binary:logistic', random_state=0,
reg_alpha=0, reg_lambda=1, scale_pos_weight=1, seed=None,
silent=None, subsample=1, verbosity=1)Best Parameters
------------------------
{'colsample_bytree': 1, 'gamma': 0.0, 'learning_rate': 0.1, 'max_depth': 10, 'n_estimators': 100}
Out[43]:
{'colsample_bytree': 1,
'gamma': 0.0,
'learning_rate': 0.1,
'max_depth': 10,
'n_estimators': 100}
Run models with their best parameters
#a function to train and evaluate a model with given datasets
#it also prints the accuracy scores
def run_model(model, X_train, y_train,X_test, y_test ):
model.fit(X_train, y_train)
# predict
train_preds = model.predict(X_train)
test_preds = model.predict(X_test)
# evaluate
train_accuracy = roc_auc_score(y_train, train_preds)
test_accuracy = roc_auc_score(y_test, test_preds)
report = classification_report(y_test, test_preds)
#print reports of the model accuracy
print('Model Scores')
print("------------------------")
print(f"Training Accuracy: {(train_accuracy * 100):.4}%")
print(f"Test Accuracy: {(test_accuracy * 100):.4}%")
print("------------------------------------------------------")
print('Classification Report : \n', report)
# Running RandomForestClassifier with best parameters
rf_model=RandomForestClassifier(n_estimators=100,
criterion= 'gini',
max_depth= 10,
min_samples_split= 3)
run_model(rf_model, X_train, y_train,X_test, y_test)
Model Scores
------------------------
Training Accuracy: 85.55%
Test Accuracy: 84.17%
------------------------------------------------------
Classification Report :
precision recall f1-score support
0 1.00 1.00 1.00 19940
1 1.00 0.68 0.81 60
accuracy 1.00 20000
macro avg 1.00 0.84 0.91 20000
weighted avg 1.00 1.00 1.00 20000
The accuracy dropped because I set max_depth to 10. This is kind of cut off for the model to stop after that point. The result with defauul value is higher because it goes unlimited until all leaves are the purist level. But it will take too long for a big dataset. I will keep this parameter and try to improve.
# Running XGBClassifier with best parameters
xgb_model=XGBClassifier(colsample_bytree= 1,
n_estimators= 100,
gamma= 0.1,
learning_rate=0.1,
max_depth=5
)
run_model(xgb_model, X_train, y_train,X_test, y_test)
Model Scores
------------------------
Training Accuracy: 90.83%
Test Accuracy: 87.5%
------------------------------------------------------
Classification Report :
precision recall f1-score support
0 1.00 1.00 1.00 19940
1 1.00 0.75 0.86 60
accuracy 1.00 20000
macro avg 1.00 0.88 0.93 20000
weighted avg 1.00 1.00 1.00 20000
XGBoost definetely works better with the best parameters set.
Randomforest classifier might be effected the skewness of the target. Our data is quite unbalanced. That skewness can be taken care by resampling the data via SMOTE.
3.3. Dealing with Unbalanced Data
3.3.1. Balancing Data via Oversampling with SMOTE
from imblearn.over_sampling import SMOTE
# view previous class distribution
print(target.value_counts())
# resample data ONLY using training data
X_resampled, y_resampled = SMOTE().fit_sample(X_train, y_train)
# view synthetic sample class distribution
print(pd.Series(y_resampled).value_counts())
Using TensorFlow backend.
0 99722
1 278
Name: isFraud, dtype: int64
1 79782
0 79782
dtype: int64
# perform train-test-split over resampled data
X_train, X_test, y_train, y_test = train_test_split(X_resampled, y_resampled, random_state=0)
Running models with the balanced data with best parameters¶
#Running RainForest Model with resampled data
run_model(rf_model, X_train, y_train,X_test, y_test)
Model Scores
------------------------
Training Accuracy: 99.12%
Test Accuracy: 99.01%
------------------------------------------------------
Classification Report :
precision recall f1-score support
0 1.00 0.98 0.99 19723
1 0.98 1.00 0.99 20168
accuracy 0.99 39891
macro avg 0.99 0.99 0.99 39891
weighted avg 0.99 0.99 0.99 39891
#Running XGBoost Model with resampled data
run_model(xgb_model, X_train, y_train,X_test, y_test)
Model Scores
------------------------
Training Accuracy: 99.59%
Test Accuracy: 99.47%
------------------------------------------------------
Classification Report :
precision recall f1-score support
0 1.00 0.99 0.99 19723
1 0.99 1.00 0.99 20168
accuracy 0.99 39891
macro avg 0.99 0.99 0.99 39891
weighted avg 0.99 0.99 0.99 39891
Wouw, the performence increased dramatically for both models. Having almost 100% accuracy is suspicious though. It is probably because of the synthetic data that SMOTE created. Since there are only small amount of instances for fraud class, it created too many of the same data. Model memorize that pattern and gives perfect result on the test set. Because, there is highly possible that same data points are also availble in the test set.
3.3.2. Subsampling Data from the Original Dataset
I had a huge dataset at the beginning and I did random sampling to reduce the computational laod. But I have a lot more natural fraud data point in this dataset that I can use. Insted of creating syntetic data I will choose those pints and randomly choose the safe transaction data points to get less skewed sample for my models.
#Filter the only types that fraud transaction occurs
data2=data[data['type'].isin(['TRANSFER','CASH_OUT'])]
#Slice data in to fraud and safe by isFraud values
safe_2 = data2[data2['isFraud']==0]
fraud_2 = data2[data2['isFraud']==1]
#get 50000 random sample from the safe transactions
safe_sample=safe_2.sample(n=50000, random_state=1)
safe_sample=safe_sample.sort_index()
safe_samplef=safe_sample.reset_index(drop=True)
#combine all fraud observation and 50000 safe transaction data in to df3
df3=pd.concat([safe_sample,fraud_2])
df3.reset_index(drop=True)
#drop name columns
df3=df3.drop(['nameOrig', 'nameDest'], axis=1)
#Binary-encoding of labelled data in 'type'
df3.loc[df3.type == 'CASH_OUT', 'type'] = 1
df3.loc[df3.type == 'TRANSFER', 'type'] = 0
#check class labels
df3.isFraud.value_counts()
Out[52]:
0 50000
1 8213
Name: isFraud, dtype: int64
Ok, the new dataset with totally natural data is ready for going in to our models. The proportion is still not 50% but good enough to train a model.
Running models with subsampled organic data
#Slice the target and features from the dataset
features2=df3.drop('isFraud', axis=1)
target2 =df3.isFraud
# split the data into train and test
X_train2, X_test2, y_train2, y_test2 = train_test_split(features2, target2, test_size=0.2)
# Running RandomForestClassifier with best parameters
run_model(rf_model, X_train2, y_train2,X_test2, y_test2)
Model Scores
------------------------
Training Accuracy: 93.8%
Test Accuracy: 93.45%
------------------------------------------------------
Classification Report :
precision recall f1-score support
0 0.98 1.00 0.99 10059
1 0.98 0.87 0.92 1584
accuracy 0.98 11643
macro avg 0.98 0.93 0.96 11643
weighted avg 0.98 0.98 0.98 11643
In [55]:
# Running XGBClassifier with best parameters
run_model(xgb_model, X_train2, y_train2,X_test2, y_test2)
Model Scores
------------------------
Training Accuracy: 99.4%
Test Accuracy: 98.92%
------------------------------------------------------
Classification Report :
precision recall f1-score support
0 1.00 1.00 1.00 10059
1 0.97 0.98 0.98 1584
accuracy 0.99 11643
macro avg 0.98 0.99 0.99 11643
weighted avg 0.99 0.99 0.99 11643
The results look much realistic. I can still use SMOTE on this new dataset and see how it effects the results now. But XGBoost model seems to be working clearly better in any set of data so far. Eventhough we have better proportion we still have unbalanced data. We can permofm oversampling on this new data to have more fraud data.
3.3.3 Performing SMOTE on the New Data
from imblearn.over_sampling import SMOTE
# view previous class distribution
print(target2.value_counts())
# resample data ONLY using training data
X_resampled2, y_resampled2 = SMOTE().fit_sample(X_train2, y_train2)
# view synthetic sample class distribution
print(pd.Series(y_resampled2).value_counts())
X_train2, X_test2, y_train2, y_test2 = train_test_split(features2, target2, test_size=0.2)
0 50000
1 8213
Name: isFraud, dtype: int64
1 39941
0 39941
dtype: int64
Running models with subsampled and oversampled data¶
# Running RandomForestClassifier with best parameters
run_model(rf_model, X_train2, y_train2,X_test2, y_test2)
Model Scores
------------------------
Training Accuracy: 93.77%
Test Accuracy: 92.47%
------------------------------------------------------
Classification Report :
precision recall f1-score support
0 0.98 1.00 0.99 9987
1 0.99 0.85 0.92 1656
accuracy 0.98 11643
macro avg 0.98 0.92 0.95 11643
weighted avg 0.98 0.98 0.98 11643
# Running XGBClassifier with best parameters
run_model(xgb_model, X_train2, y_train2,X_test2, y_test2)
Model Scores
------------------------
Training Accuracy: 99.45%
Test Accuracy: 98.66%
------------------------------------------------------
Classification Report :
precision recall f1-score support
0 1.00 1.00 1.00 9987
1 0.98 0.98 0.98 1656
accuracy 0.99 11643
macro avg 0.99 0.99 0.99 11643
weighted avg 0.99 0.99 0.99 11643
XGBoost improved a little bit more bu t Random Forest accuracy decreased with this new data. I can say that Random Forest can not handling too many repeted data for the sake of balancing
4. Machine Learning Pipeline
Pipelines are extremely useful tools to write clean and manageable code for machine learning.Creating a model takes a many steps such as clean our data, transform it, potentially use feature selection, and then run a machine learning algorithm. Using pipelines, we can do all these steps in one go!
#Load necessary libraries for ml pipeline
from sklearn.pipeline import Pipeline
from sklearn.preprocessing import MinMaxScaler
from sklearn.decomposition import PCA
# Create the pipeline
pipe = Pipeline([('scl', MinMaxScaler()),
('pca', PCA(n_components=7)),
('xgb', XGBClassifier())])
# Create the grid parameter
grid = [{'xgb__n_estimators': [100],
'xgb__learning_rate': [0.05, 0.1],
'xgb__max_depth': [3, 5, 10],
'xgb__colsample_bytree': [0.7, 1],
'xgb__gamma': [0.0, 0.1, 0.2]
}]
# Create the grid, with "pipe" as the estimator
gridsearch = GridSearchCV(estimator=pipe,
param_grid=grid,
scoring='accuracy',
cv=3)
# Fit using grid search
gridsearch.fit(X_train, y_train)
# Best accuracy
print('Best accuracy: %.3f' % gridsearch.best_score_)
# Best params
print('\nBest params:\n', gridsearch.best_params_)
Best accuracy: 0.995
Best params:
{'xgb__colsample_bytree': 0.7, 'xgb__gamma': 0.1, 'xgb__learning_rate': 0.1, 'xgb__max_depth': 10, 'xgb__n_estimators': 100}

5. Feature Importance
Lets check whick features are the most influencial ones for both model.
# plot the important features - based on XGBOOST
from xgboost import plot_importance
fig = plt.figure(figsize = (10, 6))
ax = fig.add_subplot(111)
colours = plt.cm.Set1(np.linspace(0, 1, 9))
ax = plot_importance(xgb_model, height = 0.5, color = 'orange', grid = False, \
show_values = False, importance_type = 'cover', ax = ax);
for axis in ['top','bottom','left','right']:
ax.spines[axis].set_linewidth(2)
ax.set_xlabel('Relative Feature Importance for XGBoost', size=12);
ax.set_yticklabels(ax.get_yticklabels(), size = 12);
ax.set_title('Feature Importance Order', size = 16);
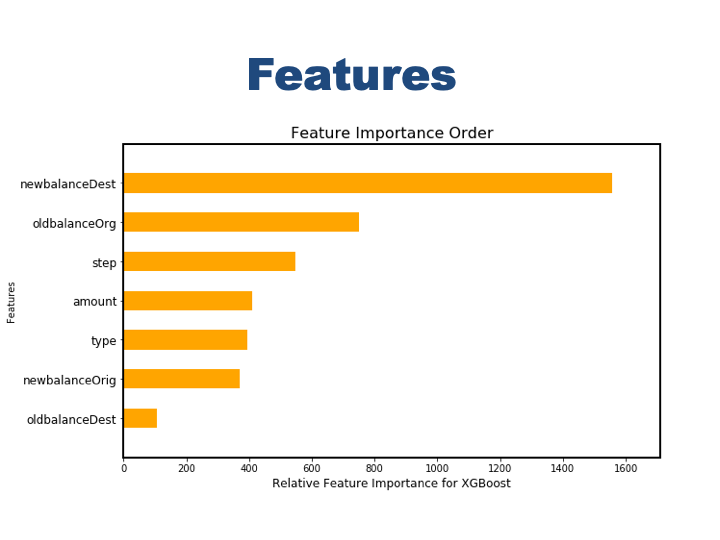 

oldbalanceOrg and newbalanceDest are the major indicators XGboost model.
6. Conclusion
Performence has increased after five iterations and finally reached to;
99% accuracy with XGBoost Classifier and Balanced Data
Most Influential Features
- Most important features are senders balance before the transaction (oldBalanceOrig) and receivers balance after the transaction (newBalanceDest).
EDA Findings
- Eventhough safe transactions slows down in 3rd and 4th day and after 16th day of the month, fraud transactions happens at a steady pace. Especially in the second half of the month there are much less safe transactions but number of fraud transactions does not decrease at all.
- Fraud proportion over all transactions is 0.01% while the fraud amount proportion is 0.1%
- There is some sort of seasonality in the number of transaction every 24 hours.Fraud transactions does not show that significant pattern. They happen every hour almost in the same frequency.
- There are more fraud transactions in low amounts and less in high amount. This distribution does not change much.
- Fraud transaction happens in a large range such as 119 dolars to 10M dolars. Most of the fraud transactions are of Lesser amount. But in 1M there is an interesting increase similar to safe transactions.
- There are 16 fake fraud cases with ‘0’ amount.
- Fraud activities only happens with TRANSFER and CASH_OUT transactions. DEBIT usage is very safe.